


去年的架構師峰會上,來自LinkedIn的高級軟件工程師Lei Gao做了一場名為《LinkedIn的數據處理架構》的演講,著重介紹LinkedIn內部的數據基礎設施的演變,其中提到Databus數據總線項目,當時就引起大家諸多好奇。前不久,LinkedIn工程團隊官方博客發布消息:Databus項目開源。
在互聯網架構中,數據系統通常分為真實數據(source-of-truth)系統,作為基礎數據庫,存儲用戶產生的寫操作;以及衍生數據庫或索 引,提供讀取和其他復雜查詢操作。後者常常衍生自主數據存儲,會對其中的數據做轉換,有時還要包括復雜的業務邏輯處理。緩存中的數據也來自主數據存儲,當 主數據存儲發生變化,緩存中的數據就需要刷新,或是轉為無效。
LinkedIn內部有很多專用的數據存儲和服務系統,構成了一個多種多樣的生態系統。基礎的OLTP數據存儲用來處理面向用戶的寫操作和部分讀操 作。其他專用系統提供負責查詢,或者通過緩存用來加速查詢結果。因此,整個生態系統中就需要一個可靠的、支持事務的、保持一致性的數據變更抓取系統。
Databus就是一個實時的低延遲數據抓取系統。從2005年就已經開始開發,2011年在LinkedIn正式進入生產系統。
在Databus的Github頁面上,介紹了他們選擇目前解決方案的決策過程。
處理這種需求有兩種常用方式:
應用驅動雙向寫:這種模式下,應用層同時向數據庫和另一個消息系統發起寫操作。這種實現看起來簡單,因為可以控制向數據庫寫的應用代碼。但是,它會 引入一致性問題,因為沒有復雜的協調協議(比如兩階段提交協議或者paxos算法),所以當出現問題時,很難保證數據庫和消息系統完全處於相同的鎖定狀 態。兩個系統需要精確完成同樣的寫操作,並以同樣的順序完成序列化。如果寫操作是有條件的或是有部分更新的語義,那麼事情就會變得更麻煩。
數據庫日志挖掘:將數據庫作為唯一真實數據來源,並將變更從事務或提交日志中提取出來。這可以解決一致性問題,但是很難實現,因為Oracle和 MySQL這樣的數據庫有私有的交易日志格式和復制冗余解決方案,難以保證版本升級之後的可用性。由於要解決的是處理應用代碼發起的數據變更,然後寫入到 另一個數據庫中,冗余系統就得是用戶層面的,而且要與來源無關。對於快速變化的技術公司,這種與數據來源的獨立性非常重要,可以避免應用棧的技術鎖定,或 是綁死在二進制格式上。
在評估了兩種方式的優劣之後,我們決定選擇日志挖掘,將一致性和單一真實數據來源作為最高優先級,而不是易於實現。
Databus的傳輸層端到端延遲是微秒級的,每台服務器每秒可以處理數千次數據吞吐變更事件,同時還支持無限回溯能力和豐富的變更訂閱功能。概要結構如下圖。

圖中顯示:Search Index和Read Replicas等系統是Databus的消費者。當主OLTP數據庫發生寫操作時,連接其上的中繼系統會將數據拉到中繼中。簽入在Search Index或是緩存中的Databus消費者客戶端,就會從中繼中拉出數據,並更新索引或緩存。
Databus提供如下功能:
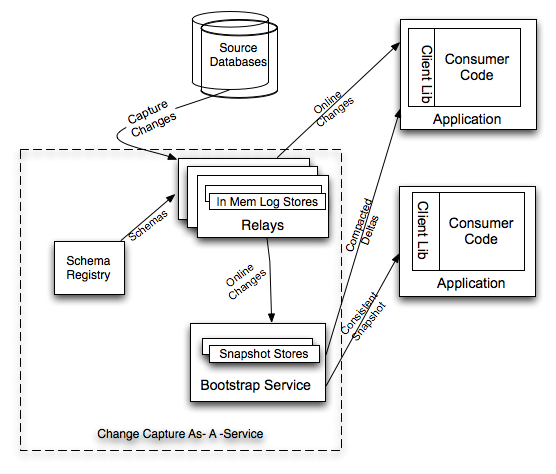
上圖中介紹了Databus系統的構成,包括中繼Relay、bootstrap服務和客戶端庫。Bootstrap服務中包括Bootstrap Producer和Bootstrap Server。快速變化的消費者直接從Relay中取事件。如果一個消費者的數據更新大幅落後,它要的數據就不在Relay的日志中,而是在 Bootstrap Producer裡面,提交給它的,將會是自消費者上次處理變更之後的所有數據變更快照。
Databus Relay中繼的功能主要包括:
Databus客戶端的功能主要包括:
Databus Bootstrap Producer只是一種特定的Databus客戶端,它的功能有:
Databus Bootstrap Server的主要功能,就是監聽來自Databus客戶端的請求,並返回長期回溯數據變更事件。
在LinkedIn,Databus支持的系統有:
對Databus項目感興趣的同學,可以去Github上查看更多信息和相關源碼。