


int a(int x)
{
return x + 5;
}
int b(int x)
{
return a(x);
}
int main(void)
{
return b(5) - 2;
}
可以看到程序中有很多函數的調用和返回。為什麼要這樣設置呢?因為程序中的函數調用時計算機工作運行的關鍵,分析函數調用的具體實現能夠幫助理解計算機運行的原理。
我們將上述代碼寫入main.c文件中。然後使用
gcc -S -o main.s main.c -m32
命令生成匯編代碼。結果如下圖。後面加-m32是為了讓其按照32位的方式反匯編。

我們只需要看匯編代碼的關鍵部分,可以把點開頭的語句全部刪去,得到如下的匯編指令。
a:
pushl %ebp
movl %esp, %ebp
movl 8(%ebp), %eax
addl $5, %eax
popl %ebp
ret
b:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl 8(%ebp), %eax
movl %eax, (%esp)
call a
leave
ret
main:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl $5, (%esp)
call b
subl $2, %eax
leave
ret
接下來我們分析C代碼和匯編程序究竟是如何對應起來的,以及匯編語言是如何工作的。
我們先看C程序,從main函數看起,它返回了一個函數b再進行運算的結果。那麼我們來看函數b,它返回的是函數a的結果,而函數a的作用是將傳遞給它的參數x加5。所以對於這個程序,最後得到的數值應該是5+5-2=8。
再來看匯編代碼,我們還是從main函數看起。一看到push,我們就知道這是在對棧進行操作。ebp是棧頂指針,esp是棧當前位置指針,棧是自上向下生長的,後進先出。先把ebp壓棧,實際上是先將esp-4再將ebp放到棧當前位置。這是第1條指令。
第2條指令將esp的值放到ebp中,也就是說現在ebp的指向改變為esp的指向。第3條指令將esp-4。第4條指令將5移入esp指向的地址中。第5條指令調用函數b,這裡等於兩個操作,一個是先將現在的eip入棧,此時eip應為subl $2,%eax這條指令的位置,我們記為28。另一個操作是將b函數的地址放入eip,也就是說此時程序要從10開始執行。
第6條指令為pushl %ebp,之前已經講過了,與7、8條一起不再贅述。第9條movl 8(%ebp), %eax,是將ebp的值+8指向的內容放入eax,實際上就是eax = 5。第10條指令將eax的內容放入現在esp指向的內容中。第11條指令調用函數a,與前面的步驟類似。第12條指令是a函數的pushl %ebp,與13、14條一同省略。第15條將eax中的值+5得到10。第16條將現在esp指向的內容放入ebp,esp+4,所以現在ebp=4。第17條指令是ret,即popl %eip,也就是現在的eip更改為18,回到函數b,從leave開始執行。第18條指令leave,表示兩條指令,movl %ebp,%esp和popl %ebp。第19條指令ret回到main函數,從28處執行。第20條指令,將eax中的內容-2,即8。第21條和第22條如圖所示。從圖中我們可以看到,棧又回到了初始的位置。
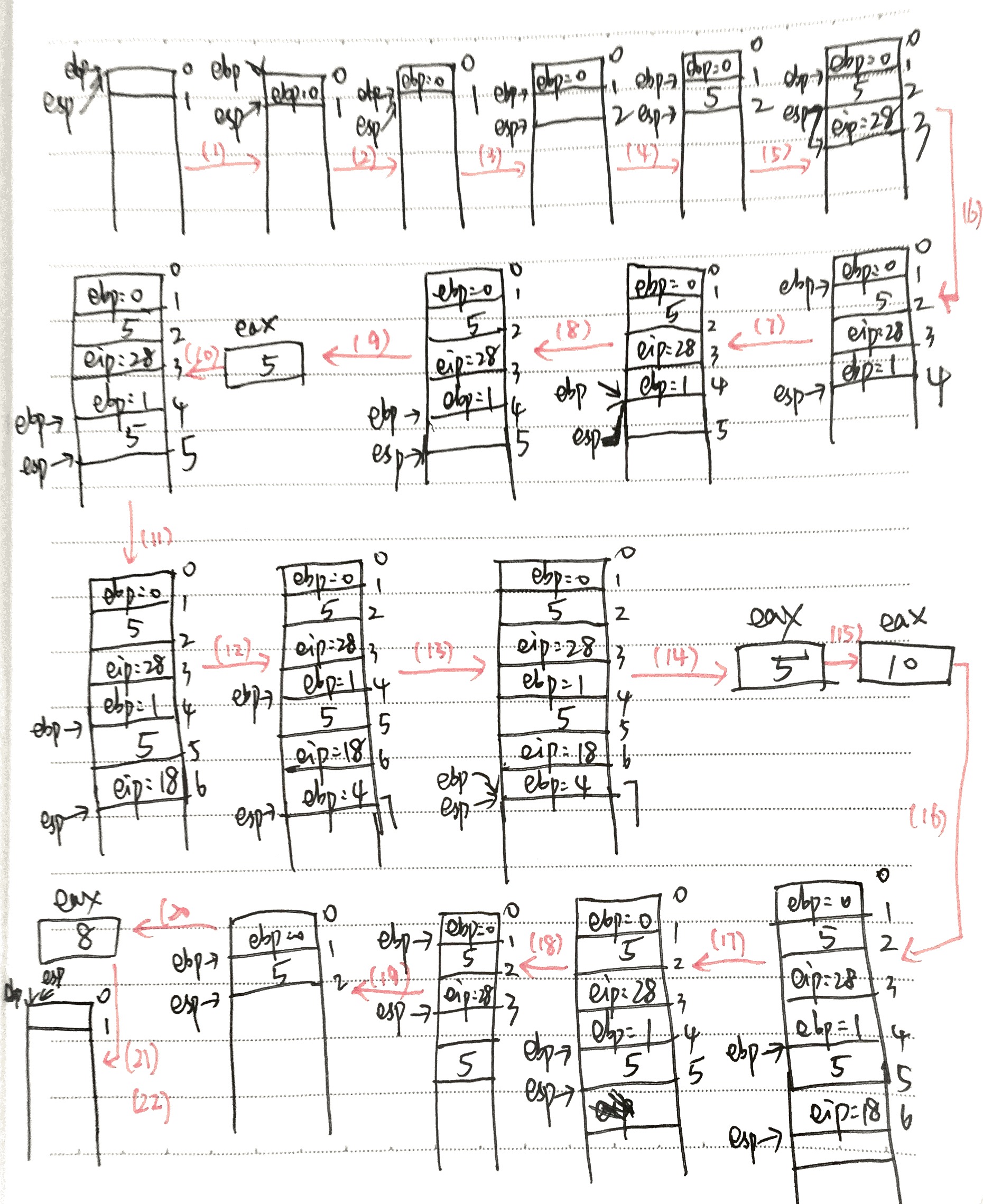 至此,匯編代碼就分析完了。
從上面的過程可以看出,計算機最本質的工作原理,是對存儲的數據進行處理,並把結果保存,然後不斷循環這個處理數據的過程。指令就是對數據進行處理的依據。具體的方法就是借助CPU中的寄存器,以及內存中的棧,依據一個約定的步驟對數據進行操作。計算機其實很簡單,它是一個認死理的家伙,只要確定了每一步要做什麼,它就會嚴格地按照步驟把操作完成,絕對不打折扣。因此,相比與人打交道,與計算機打交道可是要輕松多了。
至此,匯編代碼就分析完了。
從上面的過程可以看出,計算機最本質的工作原理,是對存儲的數據進行處理,並把結果保存,然後不斷循環這個處理數據的過程。指令就是對數據進行處理的依據。具體的方法就是借助CPU中的寄存器,以及內存中的棧,依據一個約定的步驟對數據進行操作。計算機其實很簡單,它是一個認死理的家伙,只要確定了每一步要做什麼,它就會嚴格地按照步驟把操作完成,絕對不打折扣。因此,相比與人打交道,與計算機打交道可是要輕松多了。