本文前半部分是來自http://www.qisanfen.com/?p=185的一篇文章,主要講了安裝、訓練的大致流程,注意如果需要訓練語言庫需要把所需要的庫安裝完整
後半部分大致是官方wiki的翻譯版本
如果只安裝,不訓練,可以看我的另一篇比較簡潔的文章http://blog.csdn.net/yimingsilence/article/details/51276138
關於訓練的具體細節可以查看官方wiki :https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract
或者wiki的翻譯版本http://qianjiye.de/2015/08/tesseract-ocr 和http://yanghespace.com/2015/11/01/Tesseract3訓練新語言/
安裝、訓練的大致流程
OCR的全稱是Optical Character Recognition,是指識別計算機圖片中的文字內容的過程。
Google Project下有一個C++開源項目叫做tesseract-ocr,這是一個命令行工具,運行時指定需要進行識別的圖片,識別出來的文字存儲在指定的文本文件中。它能識別包括中文在內的大多數語言,雖然初始安裝時只能正確識別比較規范的字體,但可以通過訓練提高其識別精確度。所謂訓練,實際上就是通過一系列tesseract-ocr提供的工具,根據需要識別的語言及其字體的特點,生成一個以traineddata為擴展名的文件,文件名可隨意,不過一般以語言縮寫命名,比如訓練英文生成的文件就是eng.traineddata,訓練簡體中文生成的文件就命名為chi_sim.traineddata。使用tesseract對某一圖片進行文字識別時,需要指定識別成哪一種語言,然後tesseract就會讀取對應該語言的traineddata進行識別。在我安裝的ubuntu系統下,安裝tesseract-ocr後,其使用的traineddata存放在/usr/local/share/tessdata/目錄下。因此只要將你的訓練結果復制/替換到這個目錄下,tesseract就會根據你的訓練結果來識別對應的語言了。由於安裝和訓練是獨立的,你的訓練結果可以在多個安裝環境下使用;並且,如果有人共享了識別率較高的訓練結果,你也不需要自己進行繁瑣(是的,安裝tesseract-ocr很簡單,訓練很麻煩)的訓練了。
本文記錄如何在ubuntu下安裝,使用,訓練tesseract-ocr。
詞匯說明:
tesseract-ocr是項目名稱,tesseract是安裝tesseract-ocr後用於文字識別的命令行工具名稱,本文不對兩者進行嚴格的區分。
安裝
用aptitude安裝
如果你不打算自己訓練tesseract(訓練工具得通過源代碼編譯安裝),或者想先體驗一下tesseract的功能,那麼最快速簡單的方法就是使用aptitude了。關於aptitude的用法請參考官方User
Manual。

從源代碼安裝安裝
在安裝tesseract-ocr之前,如同官方wiki文檔指出的那樣,需要先安裝一些Dependencies,包括:autotools-dev, libleptonica-dev, autoconf, automake, libtool, libpng12-dev, libtiff4-dev, zlib1g-dev, libicu-dev。這些可以用apt-get安裝,也可以用aptitude,我使用的是aptitude。wiki中還提到了libjepg62-dev,但aptitude提示其與libtiff4-dev有沖突,因此我沒有安裝,但這並不影響本文提到的tesseract的使用及基礎訓練。
接下來下載代碼,可以選擇從svn下載,也可以直接下載代碼壓縮包。svn中包含了很多語言的traineddata,總共有600多M,而單純的代碼包只有幾M。由於svn代碼較新,相對代碼壓縮包來說,多了一些本文要用到的訓練工具,因此我這裡選擇從svn下載安裝。
代碼checkout之後,在terminal下進入這個源代碼文件夾,然後按順序執行以下命令開始編譯安裝。
./autogen.sh
./configure
make
sudo make install
sudo ldconfig
到了這一步,你就可以看到 tesseract 已經被成功安裝了

安裝語言文件(Language Data)
在你用tesseract識別某一種語言之前,必須要確保你安裝了對應的語言文件(Language Data,這是tesseract-ocr訓練生成的文件,不是操作系統的語言包)。要查看是否安裝了某種語言,只需要查看 /usr/local/share/tessdata/ 目錄下是否有以該語言命名的traineddata就可以了,如果有eng.traineddata,那說名tesseract可以識別英文了,同樣,chi_sim.traineddata對應於簡體中文。
如果某種語言沒有安裝,安裝方法也很簡單,首先到官方下載列表裡面找到並下載對應語言包。比如我要識別英文,而我安裝的tesseract-ocr是3.02版本的,就下載對應版本的英文語言包
tesseract-ocr-3.02.eng.tar.gz。下載後解壓,然後將解壓出來的tesseract-ocr/tessdata/目錄下的所有文件剪切到 /usr/local/share/tessdata/ 目錄下即可。
如果你是通過build 從svn下載的代碼 來安裝的話,源代碼目錄下的tessdata子文件夾下就有tesseract能識別的各種語言的語言文件,直接將這裡的語言文件復制到 /usr/local/share/tessdata/ 目錄下就行了。或者你也可以用安裝命令來安裝語言文件,在源代碼根目錄執行以下命令進行安裝:
安裝部分語言文件
sudo make install LANGS="eng chi_sim"
安裝tesseract支持的所有語言文件
sudo make install-langs
如何卸載通過編譯源代碼安裝的tesseract-ocr
在接下來的使用、訓練過程中,如果你想要試一下不同安裝方法,你就需要知道如何卸載從源代碼安裝的tesseract-ocr。方法是在源代碼根目錄下執行以下代碼以便卸載tesseract:
sudo make uninstall
卸載過程會刪除包括 /usr/local/include/tesseract 目錄下的頭文件,/usr/local/bin 下的可執行文件,/usr/local/lib 下的庫文件,以及 /usr/local/share/tessdata 下的訓練文件在內的 tesseract 相關文件。
在源代碼的training子目錄下執行同樣的代碼即可卸載training tools。
使用
語言文件安裝完成後,就可以開始識別了。比如我有下面這張圖片 tesseract-line.png

要識別這張圖片裡面的英文,只需執行以下命令:
$ tesseract tesseract-line.png tesseract-line -l eng
這條命令裡面,第一個參數指定需要進行文字識別的圖片地址,第二個參數指定存放識別出文字的不包括擴展名的文件名,最後一個參數-l eng指定用什麼語言庫進行識別。比如這裡指定了eng,tesseract就會根據eng.traineddata進行識別。實際上traineddata文件名可以隨便取,只要使用tesseract進行文字識別的時候也用相同的名字就行了。
這裡識別的結果存在一個名為tesseract-line.txt的文件中,可以看到tesseract識別這種字體清晰的圖片還是很准確的:

訓練 ,這才是硬骨頭
前面試著用tesseract識別了一張字體清晰的圖片,接下來試一下一個比較簡單的驗證碼圖片。

這幾個字母經tesseract識別就成了MWLS,可見直接使用官方提供的語言文件時 tesseract 的識別精度是不足以實際應用的。所幸的是,tesseract-ocr提供了一系列工具用於生成自定義的語言文件,這一過程就叫做訓練。
安裝訓練工具
在進行訓練之前,首先需要安裝tesseract-ocr提供的訓練工具。
在編譯安裝訓練工具之前,還得先安裝這些包 : libicu-dev, ligpango1.0-dev, libcairo2-dev
另外,確保在源代碼根目錄下執行過以下幾條命令
./autogen.sh
./configure
make
前面提到過,這些命令也是通過源代碼安裝tesseract前必須執行的。如果前面執行過,這裡就不必再執行一遍了。這幾條命令,前兩條用於生成Makefile文件,包括根目錄及各子目錄(如training, ccutil),第三條命令是進行編譯tesseract及其依賴的一些項目。由於訓練工具也會依賴這些項目,因此在編譯訓練工具之前需要先編譯這些依賴的項目。
接下來就可以進入到源代碼的training子目錄,然後執行以下命令編譯並安裝訓練工具
$ sudo make install
訓練過程初探,前面都是准備工作,這才是重點與難點。由於訓練過程涉及到很多知識,這裡只介紹完成訓練所需要的最基本的操作方法,不細講原理,也要求訓練結果能否提高識別率。通過這一教程對訓練過程有了初步的認識後,我會在另一篇文章裡面進行更加詳細的介紹。
生成訓練圖片
首先用你要訓練的語言創建一個文本文件,比如我要訓練英文,就創建了一個名為training_text.txt的文本文件

這個文本文件必須包含你希望tesseract識別的所有字符,並且為了提高識別精度,將來在要識別的圖片中出現頻率高的字符也應該在這個文本文件裡出現更多次。接下來,需要用到一個叫做text2image的訓練工具對這個文本文件進行分析,生成一張包含這些文字的圖片,以及個字符在這張圖片上的位置信息。text2image的用法為:
$ text2image –text=training_text.txt –outputbase=[lang].[fontname].exp0 –font='Font Name' –fonts_dir=/path/to/your/fonts
可以看到,這裡需要指定一個truetype字體(字體文件以ttf為擴展名),這個字體就是你希望tesseract能夠識別的字體。在ubuntu系統的/usr/share/fonts/truetype/freefont/目錄下有一個FreeMono.ttf,這裡就以這個字體為例進行訓練
$ text2image –text=training_text.txt –outputbase=eng.freemono.exp0 –font=FreeMono –fonts_dir=/usr/share/fonts/truetype/freefont/
如果這一步執行成功,你會看到類系下面截圖的信息,並且text2image會生成兩個文件:eng.freemono.exp0.tif和eng.freemono.exp0.box,前者是包含training_text.txt文字的圖片文件,後者是一個文本文件,記錄各字符在這個圖片文件中的位置信息。如果執行成功,跳到第2步。

如果你執行text2image時碰到類似於"text2image: error while loading shared libraries: libtesseract.so.3: cannot open shared object file: No such file or directory."的報錯,那就先執行以下命令再重試,具體原因參考stackoverflow。
export LD_LIBRARY_PATH=/usr/local/lib
如果執行text2image的時候命令行輸出了幾十行的dump信息,那很可能你的tesseract-ocr不是通過源代碼編譯安裝的,我碰到個過這種情況,最後改成從源代碼編譯安裝解決。
開始訓練
用tesseract進行訓練的命令用法為:
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] box.train.stderr
用於我們前面生成的tif及box文件,就是:
tesseract eng.freemono.exp0.tif eng.freemono.exp0 box.train.stderr
正確執行的結果如下圖:
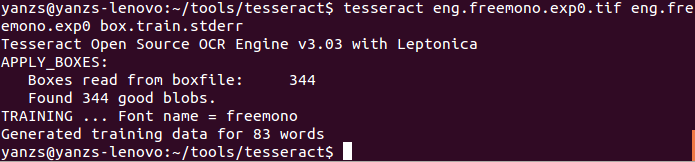
這一步會生成兩個文本文件:eng.freemono.exp0.tr和eng.freemono.exp0.txt,後者只有一些換行符,前者對應於box文件中各字符在tif圖片文件中的形狀信息,記錄的方式實際上是將一個字符看成是一個多邊形,而tr文件記錄的就是多邊形每條邊的位置、方向、長度等信息。
生成字符集信息,這需要用到一個叫unicharset_extractor的訓練工具
具體用法為:
unicharset_extractor lang.fontname.exp0.box lang.fontname.exp1.box …
我們前面只生成了一個box文件,因此執行以下命令收集字符集信息:
unicharset_extractor eng.freemono.exp0.box
成功執行的結果如下圖:

這一步會生成一個名為unicharset的文本文件,正如其名字表明的,這個文件記錄的是一個字符集,它存有box文件裡面不重復的字符信息,每個單獨字符占一行。
創建字體信息文件font_properties
由於我們可以訓練tesseract識別同一種語言的不同字體(這裡只訓練一種字體),我們需要提供字體相關的特性,這是通過一個叫做font_properties的文本文件標明的。這個文件的每一行以如下格式記錄了一個字體的信息:
<fontname> <italic> <bold> <fixed> <serif> <fraktur>
本文的訓練中使用了名為FreeMono的字體,因此font_properties裡面需要有一行以FreeMono開頭的字體信息。
除了手動創建這個文件外,tesseract-ocr源碼中也提供了一個這樣的font_properties文件(training/langdata/font_properties),並且裡面已經有了很多字體的信息,因此這裡就不許要手動創建了,後面的步驟要用的這個文件的時候,直接指定使用這個文件就行了。源代碼中的font_properties文件關於FreeMono字體的信息是:
FreeMono 0 0 1 1 0
聚合
shapeclustering, mftraining及cntraining的用法
shapeclustering -F font_properties -U unicharset lang.fontname.exp0.tr lang.fontname.exp1.tr …
mftraining -F font_properties -U unicharset -O lang.unicharset lang.fontname.exp0.tr lang.fontname.exp1.tr …
cntraining lang.fontname.exp0.tr lang.fontname.exp1.tr …
首先使用shapeclustering
shapeclustering -F source/training/langdata/font_properties -U unicharset eng.freemono.exp0.tr
成功執行結果如下圖,這一步會輸出一個名為shapetable的文件,下一步的mftraining會自動在當前目錄加載這個文件。
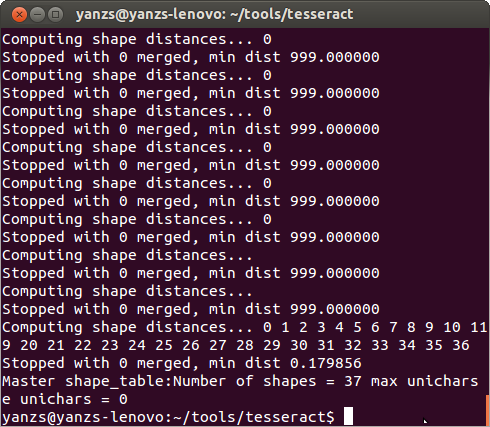
接下來執行mftraining
mftraining -F source/training/langdata/font_properties -U unicharset -O eng.unicharset eng.freemono.exp0.tr
成功執行結果如下圖(輸出結果有警告,但不影響),執行完成後會生成三個文件:eng.unicharset, inttemp, pffmtable
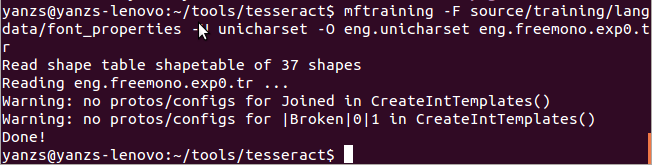
最後執行cntraining
cntraining eng.freemono.exp0.tr
成功執行的結果如下圖,這一步生成一個名為normproto的文件

合並生成traineddata文件
首先將前面生成的幾個文件(包括shapetable, normproto, inttemp, pffmtable)更名為以lang.開頭(在這裡,就是以eng.開頭,比如eng.shapetable, eng.normproto等等),然後執行以下命令將它們合並成一個traineddata文件(eng.traineddata)
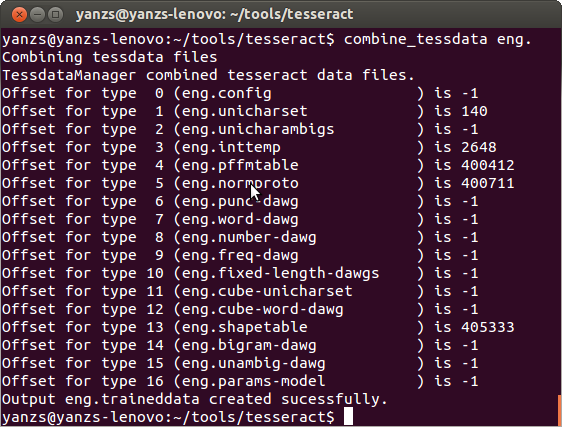
至此,訓練完畢,只需按照前述的安裝語言文件的方法安裝訓練得到的eng.traineddata就可以開始使用你的訓練成果了。需要注意的是,根據本文的訓練生成的traineddata只能識別本文最初創建的training_data.txt中存在的字符,並且只能識別字體與FreeMono接近的文字。我試著用這個traineddata識別“使用”一節中提到過的tesseract-line.png文件,會得到如下結果:
Pummg Bt a" mgemer
可見這種簡單的訓練識別率是很低的。本文只是簡單的介紹一下訓練的過程,我之後會寫一篇旨在提高識別精度的更具體的訓練過程,敬請期待。
tesseract-ocr官方wiki翻譯
這是關於如何使用Tesseract3訓練新的語言的文檔,該文檔是tesseract-ocr官方wiki上翻譯過來的。
1.介紹
Tesseract3.0x是支持訓練的。這篇文章描述如何訓練的過程,提供適用於各種語言的一些指導方針,以及訓練會得到的結果。對於Tesseract2.0x的訓練參考:TrainingTesseract.
2.背景及局限性
Tesseract原來僅僅為了識別英文而設計的。我們做了許多努力來使得識別引擎及訓練系統能夠應對不同語言及UTF-8字符。Tesseract3.0能夠處理任意的UTF-8字符,但是還是只能對部分的語言成功處理,因此在期望Tesseract能夠對你的特定語言處理前,你要注意下這個細節。
Tesseract3.01添加了從上到下排列的語言,Tesseract3.02添加了希伯來語(Hebrew)(從右到左排列)。現在Tesseract可以使用一個輔助引擎(稱為cube)來應對類似阿拉伯語(Arabic)的文本。
Tesseract對於大量字符集的語言(如中文)訓練/識別緩慢(譯者注:由於字符集非常大,增加了訓練/匹配時間),但是也能夠正常工作。
Tesseract需要了解一個字符的形狀,通過將不同字體明確分開。之前對字體數量限制在32個,現在增加到了64個。這個可以通過intproto.h中常量MAX_NUM_CONFIGS 進行設置。注意運行時間很大程度上依賴於字體數量,如果訓練字體數量大於32將會非常緩慢。
如果訓練的語有不一樣的標點及數字,會不利於一些硬編碼的算法,在這些算法中,都假設是ASCII字符集中的標點及數字。這個局限在3.0x(x>=2)版本中已經修改。
你需要在你的輸入文件路徑下運行所有的命令行。
3.所需的附加庫
從3.03版本開始,需要一些附加庫用來建立你的訓練工具:
sudo apt-get install libicu-dev
sudo apt-get install libpango1.0-dev
sudo apt-get install libcairo2-dev
4.建立訓練工具
從3.03版本開始,如果你從源碼編譯Tesseract,你需要另外使用make命令來安裝訓練工具:
make training
sudo make training-install
5.所需的數據文件
為了訓練另一種語言,需要在tessdata子目錄下創建一些數據文件,然後在使用combine_tessdata把這些文件合並成單個文件。命名約定為:languagecode.file_name,Language codes最好按照ISO639-3標准。English對應的訓練依賴文件(3.00)為:
tessdata/eng.config
tessdata/eng.unicharset
tessdata/eng.unicharambigs
tessdata/eng.inttemp
tessdata/eng.pffmtable
tessdata/eng.normproto
tessdata/eng.punc-dawg
tessdata/eng.word-dawg
tessdata/eng.number-dawg
tessdata/eng.freq-dawg
最後合並的文件為:
tessdata/eng.traineddata
並且文件
tessdata/eng.user-words
仍然可以單獨提供。合並的traineddata只是簡單的將輸入文件串聯,通過一個列表目錄記錄已知的文件類型的偏移量。可以查看源碼ccutil/tessdatamanager.h中當前接受的文件名。注意traindata中包含的文件和3.00版本之前的已經不同。並且可能在今後的修訂中大幅修改。
5.1 文本輸入文件的要求
文本輸入文件(如lang.config, lang.unicharambigs, font_properties, box files, wordlists for dictionaries…)需要滿足以下條件:
沒有BOM的ASCII或者UTF-8字符
Unix下的行結束符(‘\n’)
文件結束符為行結束符(‘\n’).否則會提示錯誤信息“ast_char == ‘\n’:Error:Assert failed…”
5.2 你可以忽略哪些?
unicharset, inttemp, normproto, pfftable這些文件是一定要創建的。如果你只要識別相似或一個字體,那麼一個簡單的訓練也就夠了。其他的文件不太需要,但是可以幫助提高精度,這要看你的需求了。老版的DangAmbigs已經被unicharambigs替代。
6.訓練過程
盡管已經有很多自動化的過程,但是有些步驟還是得手動。以後可能會有更多的自動化工具,但是需要一些復雜的安裝過程。下面這些工具都是在訓練子目錄下自帶的。
6.1 生成訓練圖片
首先確定需要的字符集,然後准備一個保護這些字符的文本。在創建訓練文件時需要牢記以下幾點:
+確保每個字符有最低的樣本數,10個的話很好,對於稀少的字符5個也OK。
對於常用的字符需要更多的樣本——至少20個。
對於標點和字符要打散。比如“The quick brown fox jumps over the lazy dog. 0123456789 !@#$%^&(),.{}<>/?”這樣就很差。最好是類似這樣排列:“The (quick) brown {fox} jumps! over the $3,456.78 #90 dog & duck/goose, as 12.5% of E-mail from aspammer@website.com
is spam?”這樣可以讓textline finding代碼對於特殊字符更好的找到baseline.
6.2 自動方式-創建tif/box文件
准備UTF-8的字符文本(training_text.txt)包含你所需要的字符。獲取你想要識別的字符字體(trueType(微軟和Apple公司共同研制的字型標准)或者是其他字體)。對於每一種字體運行下面的命令行,創建對應的tif/box文件:
training/text2image —text=training_text.txt —outputbase=[lang].[fontname].exp0 —font=’Font Name’ —fonts_dir=/path/to/your/fonts
注意參數—font可以包含空格,因此必須加上引號,例如:
training/text2image —text=training_text.txt —outputbase=eng.TimesNewRomanBold.exp0 —font=’Times New Roman Bold’ —fonts_dir=/usr/share/fonts
text2image還有許多其他命令行參數,可以查看traning/text2image.cpp獲取更多信息。
如果你的應用可以使用text2image,非常好!你可以直接跳到6.4運行tesseract進行訓練。
6.3 手動方式-創建tif/box文件
6.3.1 獲取tif圖像在打印文本時需要凸出空格,因此在文本編輯器中就需要增大字符間距及行間距。不充足的空格距離可能導致生成*.tr文件時彈出“FAILURE! box overlaps no blobs or blobs in multiple rows”錯誤信息,而這又會導致另一個錯誤————某個字符”x”沒有樣本,然後彈出“”Error: X classes in inttemp while unicharset contains Y unichars”,這樣的訓練數據就不能用了。以後我們會解決這種問題,但是3.00的版本還是會出現這種情況。
訓練文件應該要以字體區分。理想的情況是單一字符的所有樣本都在同一個tiff圖像中,但這樣可能需要多頁tiff(如果你安裝了libtiff或者是leptonica),這樣單一的字體中包含的訓練數據可能有很多頁並且包含成千上萬的字符,同時允許對大字符集語言進行訓練。
不要再一個圖像文件中混淆字體這會導致聚類時特征的丟失,從而導致識別錯誤。
下一步就是打印並掃描圖像,用來創建你的訓練頁。最多支持64個訓練頁。最好創建包含斜體及黑體的混合的字體及樣式(但是要在不同的文件中)。
注意對真實圖像進行訓練有點困難,這是由於間隔寬度的要求。這在今後的版本中會得到改善。
同時你需要保存一份包含訓練文本的UTF-8的文件,在後面的步驟中將會用到。
對於大量的訓練數據說明.64個圖片是對字體個數的限制。每個字體應該放在單一的多頁tiff文件中,並且box文件可以對指定頁碼的字符坐標修改。因此對於給定字體可以創建任意數量的訓練數據,也運行對大字符集語言進行訓練。對於一個字體,也可以用多個單頁tiff文件來代替多頁tiff文件, and then you must cat together the tr files for each font into
several single-font tr files.不管如何,輸入給mftraining的tr文件,必須各自包含單個字體。
6.3.2生成box文件下一步,Tesseract對每個訓練圖像需要一個’box’文件。box文件是一個文本文件,按序排列了訓練圖片的字符及字符的外包矩形框坐標。Tesseract3.0有一個模式可以生成所需格式的box文件,然後你需要手動編輯這個box文件,使得正確的字符和位置能夠對應。
對每個訓練圖片運行如下命令行:
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
例如:
tesseract eng.timesitalic.exp0.tif eng.timesitalic.exp0 batch.nochop makebox
現在是最困難的地方。你需要對[lang].[fontname].exp[num].box文件進行編輯,你需要在每一行開始的位置輸入正確的UTF-8格式字符,來代替Tesseract自動生成的錯誤的字符。例如,下面是例子圖片eurotext.tif的輸出box文件(第141-154行):
s 734 494 751 519 0
p 753 486 776 518 0
r 779 494 796 518 0
i 799 494 810 527 0
n 814 494 837 518 0
g 839 485 862 518 0
t 865 492 878 521 0
u 101 453 122 484 0
b 126 453 146 486 0
e 149 452 168 477 0
r 172 453 187 476 0
d 211 451 232 484 0
e 236 451 255 475 0
n 259 452 281 475 0
由於Tesseract是在英文模式下運行的,它不能正確的識別變音符號。這個需要一個合適的編輯器來輸入。一個支持UTF-8的編輯器就夠了,HTML編輯器是個不錯的選擇(linux下的Mozilla可以直接編輯UTF-8文本,Firefox和IE浏覽器則不支持)。MS的Word支持不同的字符編碼,Notepad++也支持。Linux和Windows都有一個字符列表用來拷貝不能手打的字符。如用ü代替u。
理論上,每一行都只有一個字符。但是在水平方向上分離的一個字符,可能被單成兩個,例如下雙引號“„”,你需要合並這兩個box:例如,第116-229行:
D 101 504 131 535 0
e 135 502 154 528 0
r 158 503 173 526 0
, 197 498 206 510 0
, 206 497 214 509 0
s 220 501 236 526 0
c 239 501 258 525 0
h 262 502 284 534 0
n 288 501 310 525 0
e 313 500 332 524 0
l 336 501 347 534 0
l 352 500 363 532 0
e 367 499 386 524 0
” 389 520 407 532 0
注意2,3列表示左上角坐標lefttop,4,5列表示右下角坐標rightbottom,最後一列是對應的多頁tiff圖像中的頁碼。坐標系以圖上左上角為原點。合並後的結果:
D 101 504 131 535 0
e 135 502 154 528 0
r 158 503 173 526 0
„ 197 497 214 510 0
s 220 501 236 526 0
c 239 501 258 525 0
h 262 502 284 534 0
n 288 501 310 525 0
e 313 500 332 524 0
l 336 501 347 534 0
l 352 500 363 532 0
e 367 499 386 524 0
” 389 520 407 532 0
已經有許多個可視化Box編輯器,請點擊AddOns wiki.
6.3.3引導新的字符集如果你訓練的是全新的字符集,你可以先使用一種字體來獲取box文件,再運行下面的訓練步驟生成一個traindata,然後再使用Tesseract處理其他的字體的box文件:
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] -l yournewlanguage batch.nochop makebox
這樣能提高你的box文件中的字符正確率,減少編輯。你可以用這種方法來增加新的字體,但是要注意沒有一種訓練模式可以在已有的traindata中添加新的訓練數據。這意味著每一次你運行mfTraining和cnTraining都是從你提供的tr文件創建一個新的數據文件,並不可以直接在現有的intproto/pffmtable/normproto中直接添加。
6.3.4 tif/box文件要一一對應一些tif/box文件可以在下載頁面下載。(注意tif文件經過G4壓縮,要使用libtiff進行解壓縮)。你可以按照下面操作獲取更好的訓練數據:
過濾box文件,保留你想要的字符行。
運行tesseract進行訓練(後面介紹)。
在多種語言中獲取你想要字符的每種字體的tr文件,並且添加你自己的字體或者字符。
以相同的方式獲取已過濾的box文件到.tr文件中,以便在unicharset_extractor中處理。
進行剩余的訓練過程。
注意!這沒有想象的那麼簡單!(cntraining and mftraining can only take up to 64 .tr files, so you must cat all the files from multiple languages for the same font together to make 64 language-combined, but font-individual files. The characters found in the tr files
must match the sequence of characters found in the box files when given to unicharset_extractor, so you have to cat the box files together in the same order as the tr files. The command lines for cn/mftraining and unicharset_extractor must be given the .tr
and .box files (respectively) in the same order just in case you have different filtering for the different fonts. There may be a program available to do all this and pick out the characters in the style of character map. This might make the whole thing easier)
跳轉到的地方
6.4 運行tesseract進行訓練
對每一對訓練圖片和box文件,運行下面命令行:
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] box.train
或者
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] box.train.stderr
第一個命令行會把所有錯誤信息記錄在tesseract.log中。第二個命令行會在stderr中輸出。
注意box文件名和tif文件名要相同,並且在相同路徑下,否則Tesseract會找不到。輸出文件為fontfile.tr,這個文件保護訓練頁中每個字符的特征。[lang].[fontname].exp[num].txt will also be written with a single newline and no text.
重要的是檢查apply_box輸出中是否有錯誤。如果存在FATALITIES報告,那麼沒有必要繼續訓練過程指導你修復了box文件。新的box.train.stderr配置文件讓輸出的定位變得更簡單。一個FATALITY通常提示當前步驟在你的box文件中尋找某個字符的訓練樣本時失敗。不是坐標錯了,就是圖片中對應字符圖片出錯了。如果一個字符不存在可以操作的樣本,它就不能被識別,生產的inttemp文件也不會匹配unicharset文件,Tesseract將中止。
另一個可能出現的錯誤也是致命的——“Box file format error on line n”。If preceded by “Bad utf-8 char…” then the utf-8 codes are incorrect and need to be fixed. The error “utf-8 string too long…” indicates that you have exceeded the 24 byte limit on a character description.
If you need a description longer than 24 bytes, please file an issue.
沒有必要對[lang].[fontname].exp[num].tr文件的內容進行編輯。下面是tr文件的一些格式:
Every character in the box file has a corresponding set of entries in
the .tr file (in order) like this
UnknownFont 2
mf
x y length dir 0 0
… (there are a set of these determined by
above)
cn 1
ypos length x2ndmoment y2ndmoment
The mf features are polygon segments of the outline normalized to the
1st and 2nd moments.
x= x position [-0.5.0.5]
y = y position [-0.25, 0.75]
length is the length of the polygon segment [0,1.0]
dir is the direction of the segment [0,1.0]
The cn feature is to correct for the moment normalization to
distinguish position and size (eg c vs C and , vs ‘)
6.5 計算字符集
Tesseract需要知道它tractor可以輸出的字符集。為了生成unicharset數據文件,使用unicharset_ex程序處理box文件:
unicharset_extractor lang.fontname.exp0.box lang.fontname.exp1.box …
Tesseract訪問字符的屬性:isalpha, isdigit, isupper, islower, ispunctuation。該數據而可以以unicharset的數據形式被編碼。每一行對應一個字符。UTF-8的後面是表示二進制掩碼編碼性質的十六進制數。每個bit表示一個屬性。如果bit設置為1,表示該屬性為真。這些為按順序排列(從最低位到最高位): isalpha, islower, isupper, isdigit, ispunctuation。
例子:
“;”是標點,它的屬性表示為10000(0x10)。
“b”是字母表中的小寫字符,它的屬性表示為00011(0x3)。
“W”屬性為00101(0x5)。
“7”屬性為01000(0x8)。
“=”既不是標點也不是字母,屬性為00000(0x0)。
; 10 Common 46
b 3 Latin 59
W 5 Latin 40
7 8 Common 66
= 0 Common 93
中文和日文的字符也在最低位表示,如00001(0x1)。
如果你的系統支持寬字符處理函數,這些值都將通過unicharset_extractor自動設置,沒有必要自己編輯。老的系統(如Windows95)可能要手動編輯。
注意unicharset文件必須在inttemp, normproto和pffmtable生成時重新生成(換言之,這些文件在box文件改變時必須重新創建)。
最後兩列表示腳本類型(Latin, Common, Greek, Cyrillic, Han, null)和給定語言的字符編碼。
6.5.1 set_unicharset_properties(3.03版本新增)在3.03中新的工具和數據文件可以用來添加額外的屬性,大部分是字符的大小:
training/set_unicharset_properties -U input_unicharset -O output_unicharset —script_dir=training/langdata
6.6 font_properties(3.01版本新增)
在3.01中訓練過程需要font_properties文件。這個文件的目的是提供字體信息,以便在識別出來的結果中給出字體信息。font_properties是通過mftraining的-F filename選項處理的文本文件。
font_properties每一行的格式為:
<fontname> <italic> <bold> <fixed> <serif> <fraktur>
其中<fontname>是一個字符串(不能有空格),其他<italic> <bold> <fixed> <serif> <fraktur>都是以0,1標記,表示該字體是否有該屬性。
當運行mftraining時,每個.tr文件名必須對應一個font_properties文件,否則將中止。
例子:
font_properties文件:
timesitalic 1 0 0 1 0
shapeclustering -F font_properties -U unicharset eng.timesitalic.exp0.tr
mftraining -F font_properties -U unicharset -O eng.unicharset eng.timesitalic.exp0.tr
注意在3.03中,training/langdata/font_properties是默認的font_properties文件,包含3000個字體(不一定需要)。
6.7 聚類
當所有的訓練頁中的字符特征已將被提取,我們需要對它們進行聚類。字符形狀可以通過 shapeclustering (3.02版本後允許), mftraining and cntraining programs程序進行聚類:
shapeclustering -F font_properties -U unicharset lang.fontname.exp0.tr lang.fontname.exp1.tr …
shapeclustering通過形狀聚類創建一個主字形表,並且寫入文件-shapetable。
注意:如果你沒有運行shapeclustering,mftraining也會產生一個shapetable.你必須在你的traindata中包含這個shapetable,不管shapeclustering是否運行過。
mftraining -F font_properties -U unicharset -O lang.unicharset lang.fontname.exp0.tr lang.fontname.exp1.tr …
-U 文件表示由上面的unicharset_extractor生成的unicharset,lang.unicharset是輸出文件,提供給combine_tessdata處理。mftraining會輸出另外兩個數據文件:inttemp(字符形狀原型the shape prototypes)和pffmtable(每個字符期望的特征個數the number of expected features for each character)。(另外一個文件Microfeat也會生成,但是沒有用。)
cntraining lang.fontname.exp0.tr lang.fontname.exp1.tr …
這個生成normproto數據文件(字符歸一化敏感度原型the character normalization sensitivity prototypes)。
6.8 字典數據(可選)
Tesseract為每個語言最多使用8個字典文件。它們都是可選的,用來幫助Tesseract不同字符組合的可能性。
有7個文件編碼為Directed Acyclic Word Graph(DAWG),另一個是簡單的UTF-8文本:
為了生成DAWG字典文件,你首先需要你所訓練語言的單詞表。你可以從拼寫檢查中發現一個合適的字典(如ispell, aspell和hunspell)————注意license。單詞表用UTF-8的格式表示的話一個單詞一行。把單詞量拆成需要的集合,如:頻繁出現的單詞,剩余的單詞,然後使用wordlist2dawg用來生成DAWG文件:
| Name | Type | Description | word-dawgdawgA dawg made from dictionary words from the language.freq-dawgdawgA dawg made from the most frequent words which would have gone into word-dawg.punc-dawgdawgA dawg made from punctuation patterns found around words. The “word” part is replaced by a single space.number-dawgdawgA dawg made from tokens which originally contained digits. Each digit is replaced by a space character.fixed-length-dawgsdawgSeveral dawgs of different fixed lengths —— useful for languages like Chinese.bigram-dawgdawgA dawg of word bigrams where the words are separated by a space and each digit is replaced by a ?.unambig-dawgdawgTODO: Describe.user-wordsdawgA list of extra words to add to the dictionary. Usually left empty to be added by users if they require it; see tesseract(1).
wordlist2dawg frequent_words_list lang.freq-dawg lang.unicharset
wordlist2dawg words_list lang.word-dawg lang.unicharset
注意如果合並的traindata中包含字典,字典不能為空。
如果你需要字典的例子文件,解壓(通過combine_tessdata)已有的語言文件(如eng.traineddata)並且使用dawg2wordlist提取單詞表。
6.9 最後一個文件(unicharambigs)
這個文件描述了字符之間的模糊集。通常都是手動生成。為了理解格式,查看以下示例:
v1
2 ‘ ‘ 1 “ 1
1 m 2 r n 0
3 i i i 1 m 0
第一行是一個版本標識符。下面的行以tab制表符分割,使用下面的格式:
type indicator可以有下面的值:
| Value | Type | 0A non-mandatory substitution. This informs tesseract to consider the ambiguity as a hint to the segmentation search that it should continue working if replacement of ‘source’ with ‘target’ creates a dictionary word from a non-dictionary word. Dictionary
words that can be turned to another dictionary word via the ambiguity will not be used to train the adaptive classifier.1A mandatory substitution. This informs tesseract to always replace the matched ‘source’ with the ‘target’ strings.
| Example line | Explanation | 2 ‘ ‘ 1 “ 1A double quote (“) should be substituted whenever 2 consecutive single quotes (‘) are seen.1 m 2 r n 0The characters ‘rn’ may sometimes be recognized incorrectly as ‘m’.3 i i i 1 m 0The character ‘m’ may sometimes be recognized incorrectly as the sequence ‘iii’.每個字符都必須在unicharset中有包含。就是說,這些字符都應該是訓練語言的一部分。
3.03版本支持新的更簡單的格式:
v2
‘’ “ 1
m rn 0
iii m 0
其中1表示強制,0表示可選。
unicharambigs文件也是可選的。
6.10 合並所有文件
全部情況就這樣!現在你只需要合並所有的文件(shapetable, normproto, inttemp, pffmtable),用相同的前綴重命名它們,如lang.,這裡的lang是3個字符碼,對於你要訓練的語言名字,可以在http://en.wikipedia.org/wiki/List_of_ISO_639-2_codes中找到對應的。然後運行combine_tessdata:
combine_tessdata lang.
注意:不要忘記最後一個點!
結果的lang.traineddata在你的tessdata目錄中。然後你就可以用你訓練的語言識別文本了:
tesseract image.tif output -l lang
更多的選項請請參考combine_tessdata的手冊或者源碼。


